Slo
Eng
Society
Nature
Technology
On Science
What is Alternator?
Who is Alternator?
Archive
Radio shows
Writing for Alternator
Please send articles and pitches (or questions) to
urednistvo@alternator.science
.
Contact us
Short
Long
Facebook
Instagram
Search
Long
navigation technology
environmental informatics
computer science
communication
comparative literature
ecology
social criticism
forestry
science journalism
media
meteorology
citizen science
human migration
fauna
pedagogy
psychology
etymology
culturology
traffic
agronomy
aviation
archaeology
popular culture
phraseology
art history
historiography
space physics
heritage science
press
musicology
biomedicine
karstology
self-reflection
philosophy of science
quantum mechanics
linguistics
machine learning
law
biology
diplomatics
recycling
cultural heritage
pharmacy
intelligence agency
environment
mechanics
ethnology
microbiology
theology
bioinformatics
electrical engineering
oceanography
complex matter
environmental protection
geophysics
political sociology
informatics
ethology
quantum information science
philosophy
physics
education
real estate
education
climate
film studies
paleoanthropology
gastronomy
avant-garde
psychoanalysis
manufacturing
history of science
medicine
memory studies
botany
aesthetics
astronomy
chemical technology
biochemistry
robotics
political science
gene therapy
nuclear physics
mathematics
feminism
immunology
geography
sociology
wood industry
science communication
pandemic
history
sociolinguistics
neuroscience
flora
open access
construction
natural history
economy
toxicology
genetics
Engineering
anthropology
electrochemistry
literature
art
political science
mental health
restoration
social media
lexicology
epistemology
geology
science
photography
cosmology
chemistry
funding of science
population
populism
digitization
politics
translation studies
ethics
literary studies
artificial intelligence
mariculture
architecture
astrophysics
biotechology
virology
film theory
energetics
evolution
soft matter
technology
protestantism
Long
/
On Science
Keplerjeva mehanika in astrobiologija med znanostjo in znanstveno fantastiko
Matjaž Ličer
Long
/
Nature
Skrita ljubezenska predstava murnov: dvorjenje s petjem in plesom
Nataša Stritih Peljhan
,
Alenka Žunič Kosi
Long
/
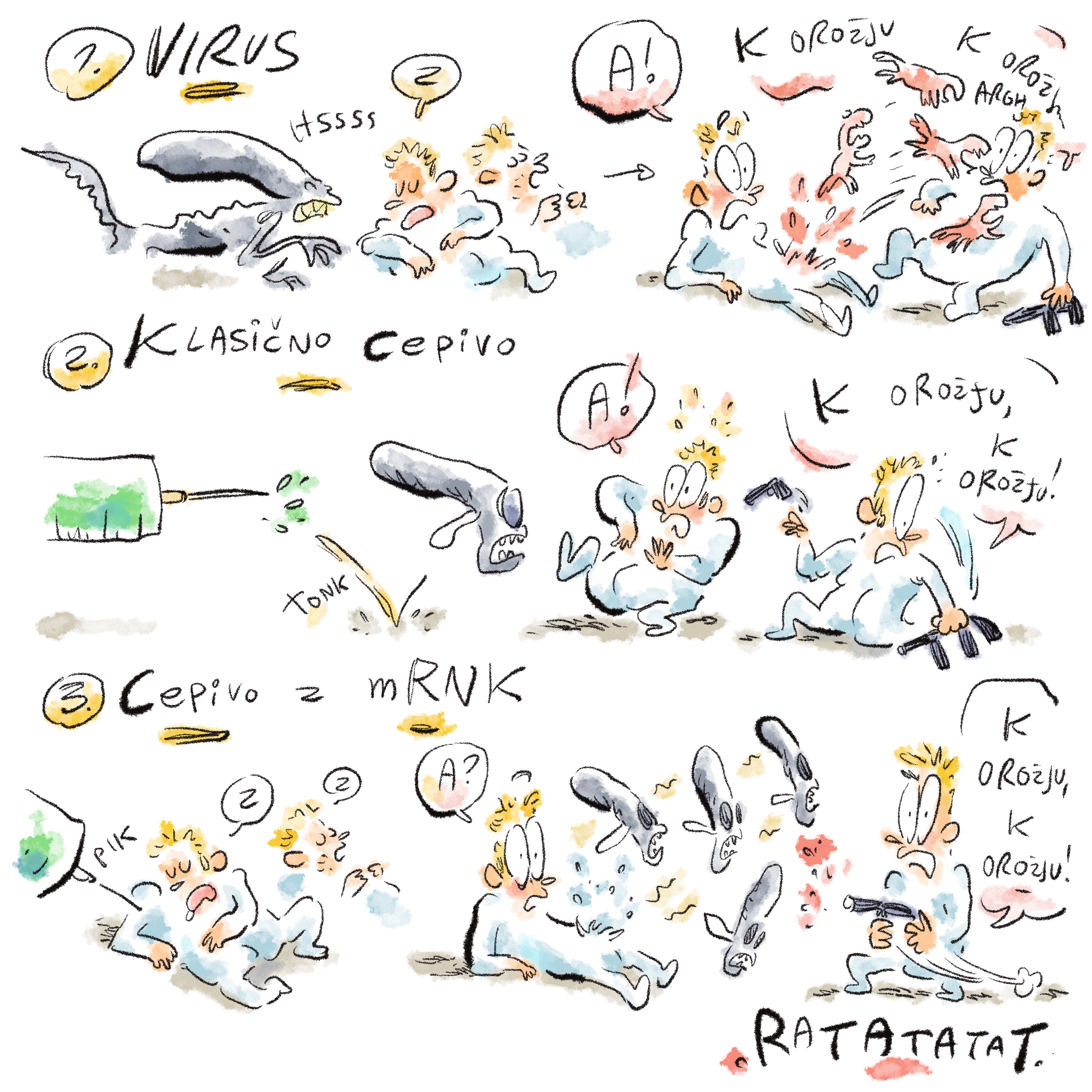
Technology
Kako nastajajo cepiva mRNK: tehnološki izzivi in rešitve iz laboratorija
Rok Sekirnik
Long
/
Nature
Praktična kvantna moč: narava kot svoj lastni računalnik
Jaka Vodeb
Long
/
Society
Intimni svetovi v ogledalu zgodovine: o raziskovanju družinske zgodovine
Barbara Vodopivec
Long
/
Nature
Zemljino magnetno polje in njegovo opazovanje v Sloveniji
Rudi Čop
Long
/
Technology
Računalniški mikroskop: raziskovanje skrivnosti atomskih svetov z molekulskimi simulacijami
Barbara Herlah
,
Andrej Perdih
Long
/
Society
Branje med vrsticami: literarna veda v kontekstu biblioterapije
Manca Marinčič
Long
/
Society
Podredje, priredje in vse med njima
Dejan Gabrovšek
Load more
1
of 22
Next